Note
Go to the end to download the full example code.
Early stopping
This script shows how to use early stopping from PyntBCI for decoding c-VEP data. Early stopping refers to determining when to stop the processing or decoding of a trial based on the reliability of the input data. Early stopping may be of two kinds: static stopping and dynamic stopping. In static stopping, an optimal fixes stopping time is learned, while in dynamic stopping the optimal stopping time depends on reaching a certain criterium, which may naturally lead to a variable stopping time.
The data used in this script come from Thielen et al. (2021), see references [1] and [2].
References
import os
import matplotlib.pyplot as plt
import numpy as np
import seaborn
import pyntbci
seaborn.set_context("paper", font_scale=1.5)
Set the data path
The cell below specifies where the dataset has been downloaded to. Please, make sure it is set correctly according to the specification of your device. If none of the folder structures in the dataset were changed, the cells below should work just as fine.
path = os.path.join(os.path.dirname(pyntbci.__file__)) # path to the dataset
subject = "sub-01" # the subject to analyse
The data
The dataset consists of (1) the EEG data X that is a matrix of k trials, c channels, and m samples; (2) the labels y that is a vector of k trials; (3) the pseudo-random noise-codes V that is a matrix of n classes and m samples. Note, the codes are upsampled to match the EEG sampling frequency and contain only one code-cycle.
# Load data
fn = os.path.join(path, "data", f"thielen2021_{subject}.npz")
tmp = np.load(fn)
X = tmp["X"]
y = tmp["y"]
V = tmp["V"]
fs = int(tmp["fs"])
fr = 60
print("X", X.shape, "(trials x channels x samples)") # EEG
print("y", y.shape, "(trials)") # labels
print("V", V.shape, "(classes, samples)") # codes
print("fs", fs, "Hz") # sampling frequency
print("fr", fr, "Hz") # presentation rate
# Extract data dimensions
n_trials, n_channels, n_samples = X.shape
n_classes = V.shape[0]
# Read cap file
capfile = os.path.join(path, "capfiles", "thielen8.loc")
with open(capfile, "r") as fid:
channels = []
for line in fid.readlines():
channels.append(line.split("\t")[-1].strip())
print("Channels:", ", ".join(channels))
# ##
# Settings
# --------
# Some general settings for the following sections
# Set trial duration
trial_time = 4.2 # limit trials to a certain duration in seconds
inter_trial_time = 1.0 # ITI in seconds for computing ITR
n_samples = int(trial_time * fs)
# Setup rCCA
encoding_length = 0.3 # seconds
onset_event = True # an event modeling the onset of a trial
event = "refe"
# Set size of increments of trials
segment_time = 0.1 # seconds
n_segments = int(trial_time / segment_time)
# Set chronological cross-validation
n_folds = 5
folds = np.repeat(np.arange(n_folds), int(n_trials / n_folds))
X (100, 8, 2520) (trials x channels x samples)
y (100,) (trials)
V (20, 504) (classes, samples)
fs 240 Hz
fr 60 Hz
Channels: Fpz, T7, O1, POz, Oz, Iz, O2, T8
Maximum accuracy static stopping
The “maximum accuracy” method is a static stopping method that learns one stopping time that given some training data reaches the maximum classification accuracy. During testing, all trials will stop as soon as that time is reached, hence static stopping.
# Loop folds
accuracy_max_acc = np.zeros(n_folds)
duration_max_acc = np.zeros(n_folds)
for i_fold in range(n_folds):
# Split data to train and valid set
X_trn, y_trn = X[folds != i_fold, :, :n_samples], y[folds != i_fold]
X_tst, y_tst = X[folds == i_fold, :, :n_samples], y[folds == i_fold]
# Train template-matching classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="correlation")
max_acc = pyntbci.stopping.CriterionStopping(rcca, segment_time, fs, criterion="accuracy", optimization="max")
max_acc.fit(X_trn, y_trn)
# Loop segments
yh_tst = np.zeros(X_tst.shape[0])
dur_tst = np.zeros(X_tst.shape[0])
for i_segment in range(n_segments):
# Apply template-matching classifier
tmp = max_acc.predict(X_tst[:, :, :int((1 + i_segment) * segment_time * fs)])
# Check stopped
idx = np.logical_and(tmp >= 0, dur_tst == 0)
yh_tst[idx] = tmp[idx]
dur_tst[idx] = (1 + i_segment) * segment_time
if np.all(dur_tst > 0):
break
# Compute accuracy
accuracy_max_acc[i_fold] = np.mean(yh_tst == y_tst)
duration_max_acc[i_fold] = np.mean(dur_tst)
# Compute ITR
itr_max_acc = pyntbci.utilities.itr(n_classes, accuracy_max_acc, duration_max_acc + inter_trial_time)
# Plot accuracy (over folds)
fig, ax = plt.subplots(3, 1, figsize=(15, 8), sharex=True)
ax[0].bar(np.arange(n_folds), accuracy_max_acc)
ax[0].hlines(np.mean(accuracy_max_acc), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[1].bar(np.arange(n_folds), duration_max_acc)
ax[1].hlines(np.mean(duration_max_acc), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].bar(np.arange(n_folds), itr_max_acc)
ax[2].hlines(np.mean(itr_max_acc), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].set_xlabel("(test) fold")
ax[0].set_ylabel("accuracy")
ax[1].set_ylabel("duration [s]")
ax[2].set_ylabel("itr [bits/min]")
ax[0].set_title(f"Maximum accuracy early stopping: avg acc {accuracy_max_acc.mean():.2f} | " +
f"avg dur {duration_max_acc.mean():.2f} | avg itr {itr_max_acc.mean():.1f}")
# Print accuracy (average and standard deviation over folds)
print("Maximum accuracy:")
print(f"\tAccuracy: avg={accuracy_max_acc.mean():.2f} with std={accuracy_max_acc.std():.2f}")
print(f"\tDuration: avg={duration_max_acc.mean():.2f} with std={duration_max_acc.std():.2f}")
print(f"\tITR: avg={itr_max_acc.mean():.1f} with std={itr_max_acc.std():.2f}")
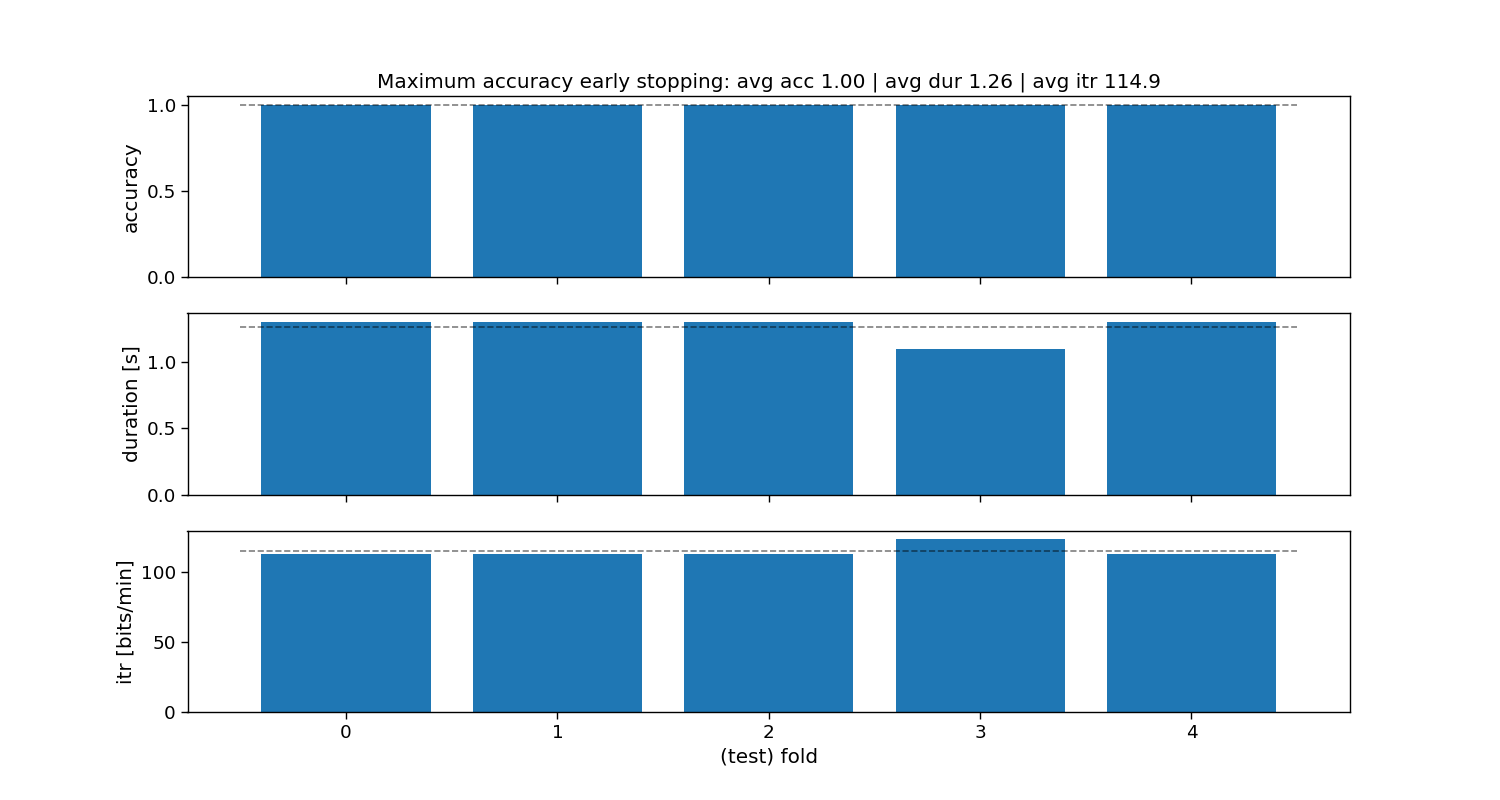
Maximum accuracy:
Accuracy: avg=1.00 with std=0.00
Duration: avg=1.26 with std=0.08
ITR: avg=114.9 with std=4.30
Maximum ITR static stopping
The “maximum ITR” method is a static stopping method that learns one stopping time that given some training data reaches the maximum information-transfer rate (ITR). During testing, all trials will stop as soon as that time is reached, hence static stopping.
# Loop folds
accuracy_max_itr = np.zeros(n_folds)
duration_max_itr = np.zeros(n_folds)
for i_fold in range(n_folds):
# Split data to train and valid set
X_trn, y_trn = X[folds != i_fold, :, :n_samples], y[folds != i_fold]
X_tst, y_tst = X[folds == i_fold, :, :n_samples], y[folds == i_fold]
# Train template-matching classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="correlation")
max_itr = pyntbci.stopping.CriterionStopping(rcca, segment_time, fs, criterion="itr", optimization="max",
smooth_width=0.3)
max_itr.fit(X_trn, y_trn)
# Loop segments
yh_tst = np.zeros(X_tst.shape[0])
dur_tst = np.zeros(X_tst.shape[0])
for i_segment in range(n_segments):
# Apply template-matching classifier
tmp = max_itr.predict(X_tst[:, :, :int((1 + i_segment) * segment_time * fs)])
# Check stopped
idx = np.logical_and(tmp >= 0, dur_tst == 0)
yh_tst[idx] = tmp[idx]
dur_tst[idx] = (1 + i_segment) * segment_time
if np.all(dur_tst > 0):
break
# Compute accuracy
accuracy_max_itr[i_fold] = np.mean(yh_tst == y_tst)
duration_max_itr[i_fold] = np.mean(dur_tst)
# Compute ITR
itr_max_itr = pyntbci.utilities.itr(n_classes, accuracy_max_itr, duration_max_itr + inter_trial_time)
# Plot accuracy (over folds)
fig, ax = plt.subplots(3, 1, figsize=(15, 8), sharex=True)
ax[0].bar(np.arange(n_folds), accuracy_max_itr)
ax[0].hlines(np.mean(accuracy_max_itr), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[1].bar(np.arange(n_folds), duration_max_itr)
ax[1].hlines(np.mean(duration_max_itr), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].bar(np.arange(n_folds), itr_max_itr)
ax[2].hlines(np.mean(itr_max_itr), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].set_xlabel("(test) fold")
ax[0].set_ylabel("accuracy")
ax[1].set_ylabel("duration [s]")
ax[2].set_ylabel("itr [bits/min]")
ax[0].set_title(f"Maximum ITR early stopping: avg acc {accuracy_max_itr.mean():.2f} | " +
f"avg dur {duration_max_itr.mean():.2f} | avg itr {itr_max_itr.mean():.1f}")
# Print accuracy (average and standard deviation over folds)
print("Maximum ITR:")
print(f"\tAccuracy: avg={accuracy_max_itr.mean():.2f} with std={accuracy_max_itr.std():.2f}")
print(f"\tDuration: avg={duration_max_itr.mean():.2f} with std={duration_max_itr.std():.2f}")
print(f"\tITR: avg={itr_max_itr.mean():.1f} with std={itr_max_itr.std():.2f}")
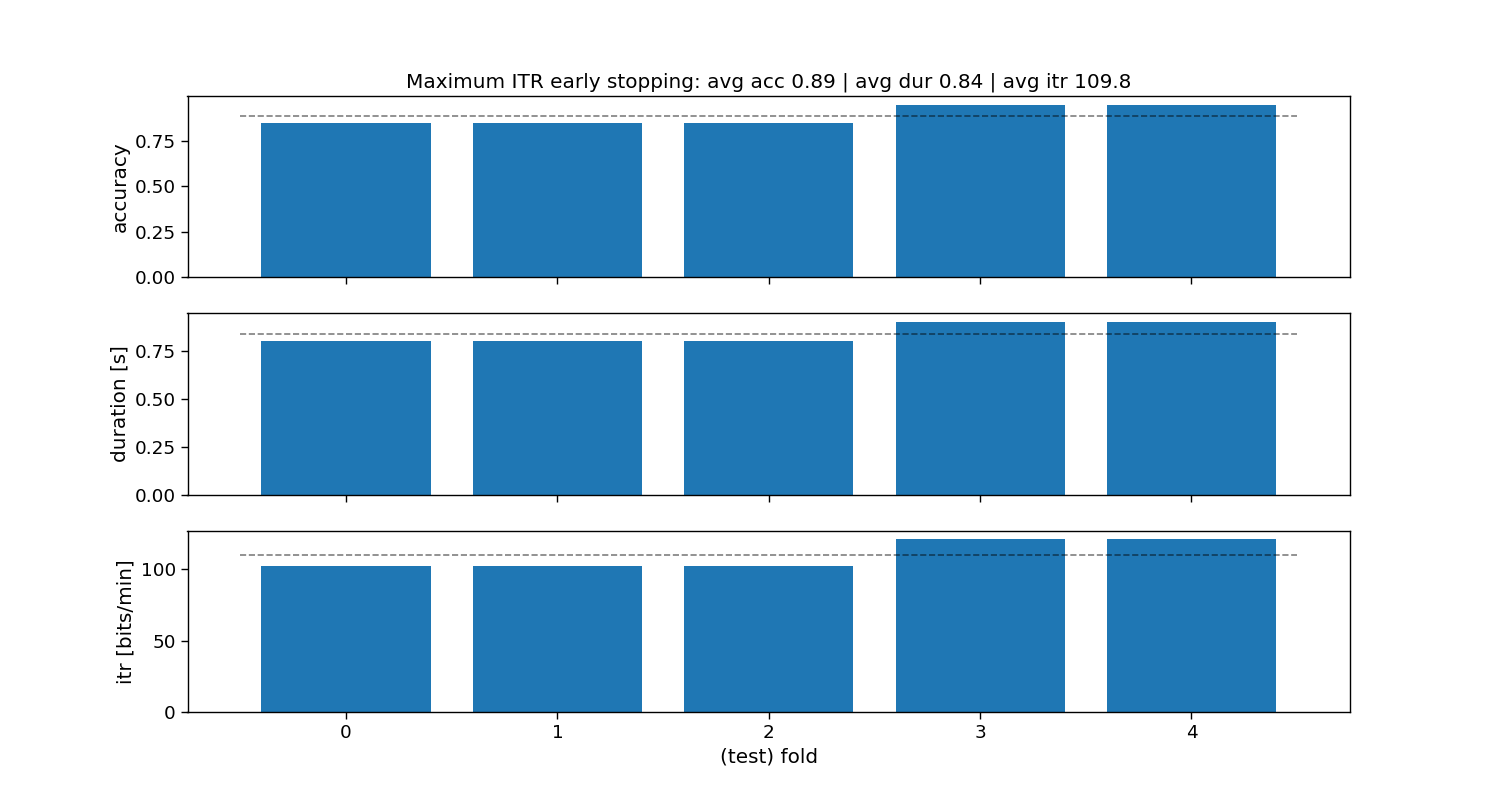
Maximum ITR:
Accuracy: avg=0.89 with std=0.05
Duration: avg=0.84 with std=0.05
ITR: avg=109.8 with std=8.93
Targeted accuracy static stopping
The “targeted accuracy” method is a static stopping method that learns one stopping time that given some training data reaches a preset targeted accuracy. During testing, all trials will stop as soon as that time is reached, hence static stopping.
# Target accuracy
target_p = 0.90 ** (1 / n_segments)
# Loop folds
accuracy_tgt_acc = np.zeros(n_folds)
duration_tgt_acc = np.zeros(n_folds)
for i_fold in range(n_folds):
# Split data to train and valid set
X_trn, y_trn = X[folds != i_fold, :, :n_samples], y[folds != i_fold]
X_tst, y_tst = X[folds == i_fold, :, :n_samples], y[folds == i_fold]
# Train template-matching classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="correlation")
tgt_acc = pyntbci.stopping.CriterionStopping(rcca, segment_time, fs, criterion="accuracy", optimization="target",
target=target_p)
tgt_acc.fit(X_trn, y_trn)
# Loop segments
yh_tst = np.zeros(X_tst.shape[0])
dur_tst = np.zeros(X_tst.shape[0])
for i_segment in range(n_segments):
# Apply template-matching classifier
tmp = tgt_acc.predict(X_tst[:, :, :int((1 + i_segment) * segment_time * fs)])
# Check stopped
idx = np.logical_and(tmp >= 0, dur_tst == 0)
yh_tst[idx] = tmp[idx]
dur_tst[idx] = (1 + i_segment) * segment_time
if np.all(dur_tst > 0):
break
# Compute accuracy
accuracy_tgt_acc[i_fold] = np.mean(yh_tst == y_tst)
duration_tgt_acc[i_fold] = np.mean(dur_tst)
# Compute ITR
itr_tgt_acc = pyntbci.utilities.itr(n_classes, accuracy_tgt_acc, duration_tgt_acc + inter_trial_time)
# Plot accuracy (over folds)
fig, ax = plt.subplots(3, 1, figsize=(15, 8), sharex=True)
ax[0].bar(np.arange(n_folds), accuracy_tgt_acc)
ax[0].hlines(np.mean(accuracy_tgt_acc), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[1].bar(np.arange(n_folds), duration_tgt_acc)
ax[1].hlines(np.mean(duration_tgt_acc), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].bar(np.arange(n_folds), itr_tgt_acc)
ax[2].hlines(np.mean(itr_tgt_acc), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].set_xlabel("(test) fold")
ax[0].set_ylabel("accuracy")
ax[1].set_ylabel("duration [s]")
ax[2].set_ylabel("itr [bits/min]")
ax[0].set_title(f"Targeted accuracy early stopping: avg acc {accuracy_tgt_acc.mean():.2f} | " +
f"avg dur {duration_tgt_acc.mean():.2f} | avg itr {itr_tgt_acc.mean():.1f}")
# Print accuracy (average and standard deviation over folds)
print("Targeted accuracy:")
print(f"\tAccuracy: avg={accuracy_tgt_acc.mean():.2f} with std={accuracy_tgt_acc.std():.2f}")
print(f"\tDuration: avg={duration_tgt_acc.mean():.2f} with std={duration_tgt_acc.std():.2f}")
print(f"\tITR: avg={itr_tgt_acc.mean():.1f} with std={itr_tgt_acc.std():.2f}")
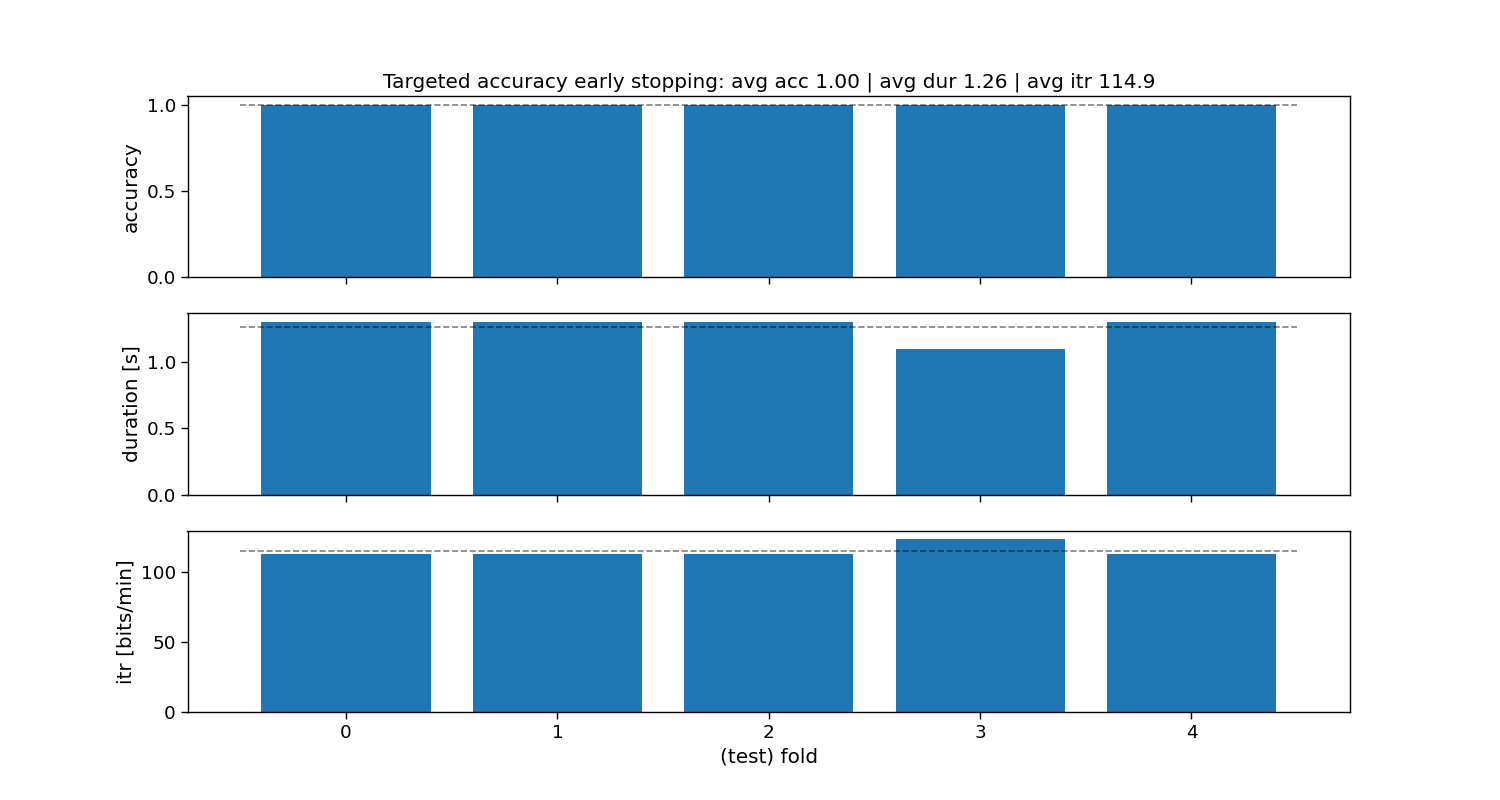
Targeted accuracy:
Accuracy: avg=1.00 with std=0.00
Duration: avg=1.26 with std=0.08
ITR: avg=114.9 with std=4.30
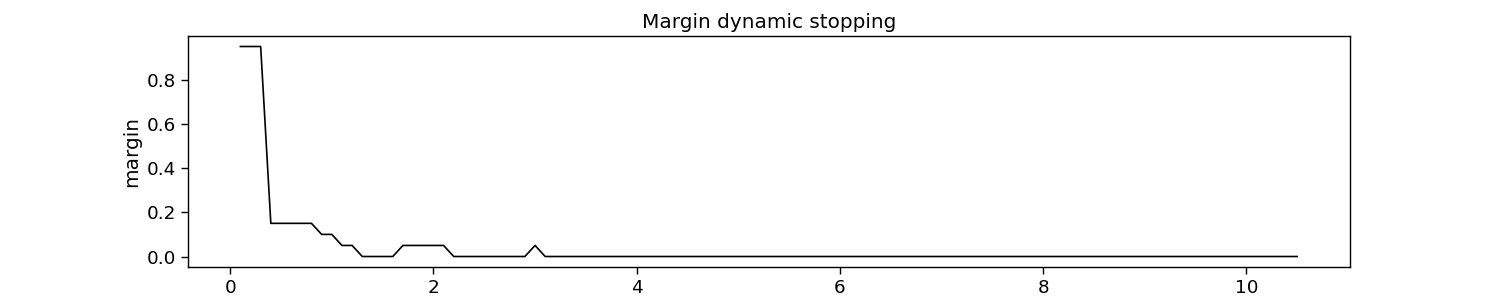
Margin dynamic stopping
The margin method learns threshold margins (i.e., the difference between the best and second-best score) to stop. These margins are defined as such that a targeted accuracy is reached.
References:
# Target accuracy
target_p = 0.90 ** (1 / n_segments)
# Fit classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="correlation")
margin = pyntbci.stopping.MarginStopping(rcca, segment_time, fs, target_p=target_p, max_time=trial_time)
margin.fit(X, y)
# Plot dynamic stopping
plt.figure(figsize=(15, 3))
plt.plot(np.arange(1, 1 + margin.margins_.size) * segment_time, margin.margins_, c="k")
plt.xlabel("time [s]")
plt.ylabel("margin")
plt.title("Margin dynamic stopping")
# Loop folds
accuracy_margin = np.zeros(n_folds)
duration_margin = np.zeros(n_folds)
for i_fold in range(n_folds):
# Split data to train and valid set
X_trn, y_trn = X[folds != i_fold, :, :n_samples], y[folds != i_fold]
X_tst, y_tst = X[folds == i_fold, :, :n_samples], y[folds == i_fold]
# Train template-matching classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="correlation")
margin = pyntbci.stopping.MarginStopping(rcca, segment_time, fs, target_p=target_p)
margin.fit(X_trn, y_trn)
# Loop segments
yh_tst = np.zeros(X_tst.shape[0])
dur_tst = np.zeros(X_tst.shape[0])
for i_segment in range(n_segments):
# Apply template-matching classifier
tmp = margin.predict(X_tst[:, :, :int((1 + i_segment) * segment_time * fs)])
# Check stopped
idx = np.logical_and(tmp >= 0, dur_tst == 0)
yh_tst[idx] = tmp[idx]
dur_tst[idx] = (1 + i_segment) * segment_time
if np.all(dur_tst > 0):
break
# Compute accuracy
accuracy_margin[i_fold] = np.mean(yh_tst == y_tst)
duration_margin[i_fold] = np.mean(dur_tst)
# Compute ITR
itr_margin = pyntbci.utilities.itr(n_classes, accuracy_margin, duration_margin + inter_trial_time)
# Plot accuracy (over folds)
fig, ax = plt.subplots(3, 1, figsize=(15, 8), sharex=True)
ax[0].bar(np.arange(n_folds), accuracy_margin)
ax[0].hlines(np.mean(accuracy_margin), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[1].bar(np.arange(n_folds), duration_margin)
ax[1].hlines(np.mean(duration_margin), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].bar(np.arange(n_folds), itr_margin)
ax[2].hlines(np.mean(itr_margin), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].set_xlabel("(test) fold")
ax[0].set_ylabel("accuracy")
ax[1].set_ylabel("duration [s]")
ax[2].set_ylabel("itr [bits/min]")
ax[0].set_title(f"Margin dynamic stopping: avg acc {accuracy_margin.mean():.2f} | " +
f"avg dur {duration_margin.mean():.2f} | avg itr {itr_margin.mean():.1f}")
# Print accuracy (average and standard deviation over folds)
print("Margin:")
print(f"\tAccuracy: avg={accuracy_margin.mean():.2f} with std={accuracy_margin.std():.2f}")
print(f"\tDuration: avg={duration_margin.mean():.2f} with std={duration_margin.std():.2f}")
print(f"\tITR: avg={itr_margin.mean():.1f} with std={itr_margin.std():.2f}")
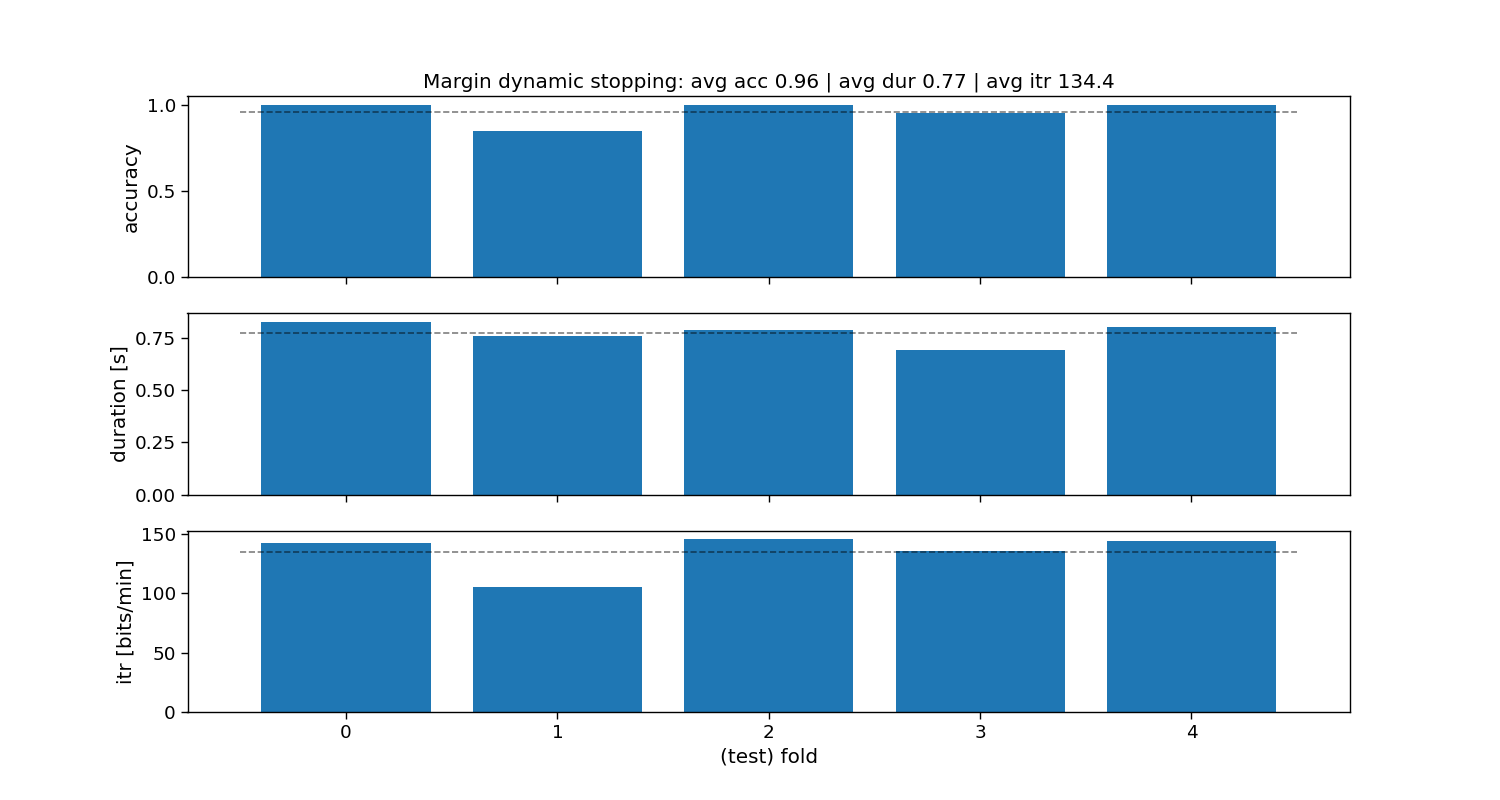
Margin:
Accuracy: avg=0.96 with std=0.06
Duration: avg=0.77 with std=0.05
ITR: avg=134.4 with std=15.15
Beta dynamic stopping
The beta method fits a beta distribution to the non-maximum scores (i.e., if correlation, then correlation+1)/2), and tests the probability of the maximum correlation to belong to that beta distribution.
References:
# Target accuracy
target_p = 0.90 ** (1 / n_segments)
# Loop folds
accuracy_beta = np.zeros(n_folds)
duration_beta = np.zeros(n_folds)
for i_fold in range(n_folds):
# Split data to train and valid set
X_trn, y_trn = X[folds != i_fold, :, :n_samples], y[folds != i_fold]
X_tst, y_tst = X[folds == i_fold, :, :n_samples], y[folds == i_fold]
# Train template-matching classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="correlation")
beta = pyntbci.stopping.DistributionStopping(rcca, target_p=target_p, fs=fs, max_time=trial_time,
distribution="beta")
beta.fit(X, y)
# Loop segments
yh_tst = np.zeros(X_tst.shape[0])
dur_tst = np.zeros(X_tst.shape[0])
for i_segment in range(n_segments):
# Apply template-matching classifier
tmp = beta.predict(X_tst[:, :, :int((1 + i_segment) * segment_time * fs)])
# Check stopped
idx = np.logical_and(tmp >= 0, dur_tst == 0)
yh_tst[idx] = tmp[idx]
dur_tst[idx] = (1 + i_segment) * segment_time
if np.all(dur_tst > 0):
break
# Compute accuracy
accuracy_beta[i_fold] = np.mean(yh_tst == y_tst)
duration_beta[i_fold] = np.mean(dur_tst)
# Compute ITR
itr_beta = pyntbci.utilities.itr(n_classes, accuracy_beta, duration_beta + inter_trial_time)
# Plot accuracy (over folds)
fig, ax = plt.subplots(3, 1, figsize=(15, 8), sharex=True)
ax[0].bar(np.arange(n_folds), accuracy_beta)
ax[0].hlines(np.mean(accuracy_beta), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[1].bar(np.arange(n_folds), duration_beta)
ax[1].hlines(np.mean(duration_beta), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].bar(np.arange(n_folds), itr_beta)
ax[2].hlines(np.mean(itr_beta), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].set_xlabel("(test) fold")
ax[0].set_ylabel("accuracy")
ax[1].set_ylabel("duration [s]")
ax[2].set_ylabel("itr [bits/min]")
ax[0].set_title(f"Beta dynamic stopping: avg acc {accuracy_beta.mean():.2f} | " +
f"avg dur {duration_beta.mean():.2f} | avg itr {itr_beta.mean():.1f}")
# Print accuracy (average and standard deviation over folds)
print("Beta:")
print(f"\tAccuracy: avg={accuracy_beta.mean():.2f} with std={accuracy_beta.std():.2f}")
print(f"\tDuration: avg={duration_beta.mean():.2f} with std={duration_beta.std():.2f}")
print(f"\tITR: avg={itr_beta.mean():.1f} with std={itr_beta.std():.2f}")
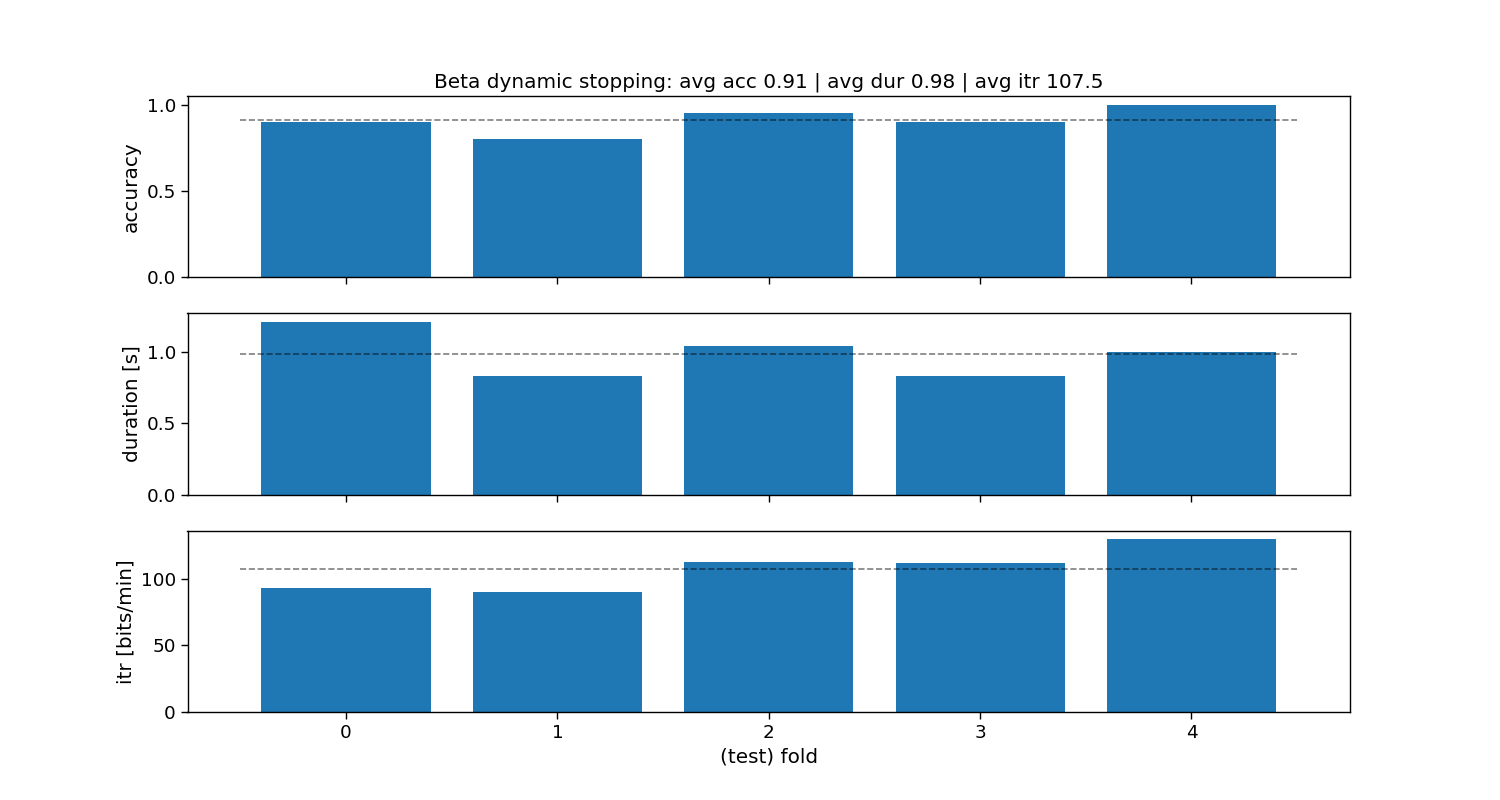
Beta:
Accuracy: avg=0.91 with std=0.07
Duration: avg=0.98 with std=0.14
ITR: avg=107.5 with std=14.46
Bayesian dynamic stopping (BDS0)
The Bayesian method fits Gaussian distributions for target and non-target responses, and calculates a stopping threshold using these and a cost criterion. This method comes in three flavours: bds0, bds1, and bds2.
References:
response brain-computer interfacing
# Cost ratio and target probabilities
cr = 1.0
# Fit classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="inner")
bayes = pyntbci.stopping.BayesStopping(rcca, segment_time, fs, cr=cr, max_time=trial_time)
bayes.fit(X, y)
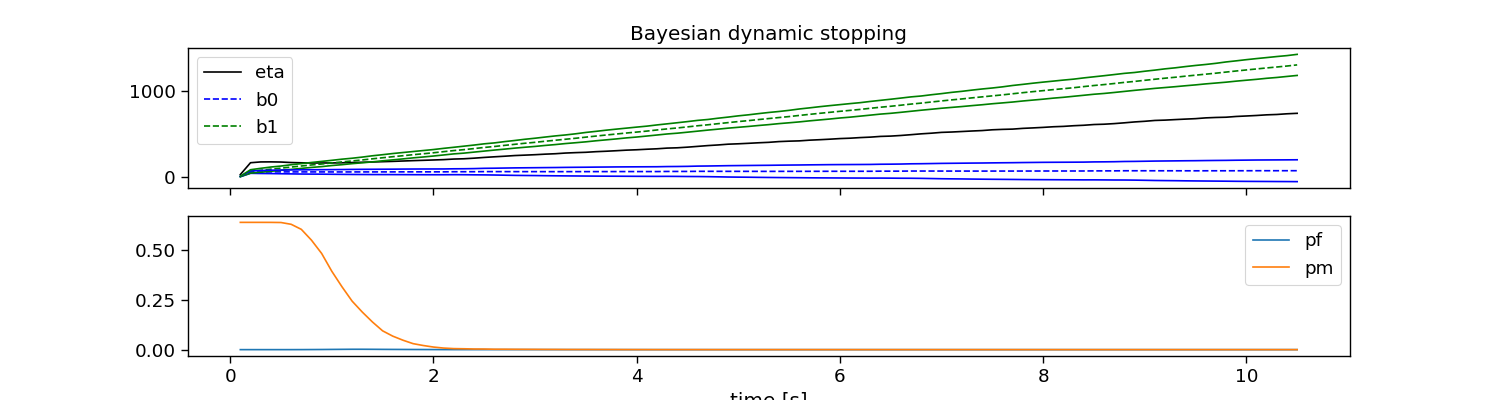
# Plot dynamic stopping
fig, ax = plt.subplots(2, 1, figsize=(15, 4), sharex=True)
ax[0].plot(np.arange(1, 1 + bayes.eta_.size) * segment_time, bayes.eta_, c="k", label="eta")
ax[0].plot(np.arange(1, 1 + bayes.eta_.size) * segment_time, bayes.alpha_ * bayes.b0_, "--b", label="b0")
ax[0].plot(np.arange(1, 1 + bayes.eta_.size) * segment_time, bayes.alpha_ * bayes.b1_, "--g", label="b1")
ax[0].plot(np.arange(1, 1 + bayes.eta_.size) * segment_time, bayes.alpha_ * bayes.b0_ - bayes.s0_, "b")
ax[0].plot(np.arange(1, 1 + bayes.eta_.size) * segment_time, bayes.alpha_ * bayes.b1_ - bayes.s1_, "g")
ax[0].plot(np.arange(1, 1 + bayes.eta_.size) * segment_time, bayes.alpha_ * bayes.b0_ + bayes.s0_, "b")
ax[0].plot(np.arange(1, 1 + bayes.eta_.size) * segment_time, bayes.alpha_ * bayes.b1_ + bayes.s1_, "g")
ax[0].legend()
ax[1].plot(np.arange(1, 1 + bayes.eta_.size) * segment_time, bayes.pf_, label="pf")
ax[1].plot(np.arange(1, 1 + bayes.eta_.size) * segment_time, bayes.pm_, label="pm")
ax[1].legend()
ax[1].set_xlabel("time [s]")
ax[0].set_title("Bayesian dynamic stopping")
# Loop folds
accuracy_bds0 = np.zeros(n_folds)
duration_bds0 = np.zeros(n_folds)
for i_fold in range(n_folds):
# Split data to train and valid set
X_trn, y_trn = X[folds != i_fold, :, :n_samples], y[folds != i_fold]
X_tst, y_tst = X[folds == i_fold, :, :n_samples], y[folds == i_fold]
# Train template-matching classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="inner")
bayes = pyntbci.stopping.BayesStopping(rcca, segment_time, fs, method="bds0", cr=cr, max_time=trial_time)
bayes.fit(X_trn, y_trn)
# Apply template-matching classifier
yh_tst = np.zeros(X_tst.shape[0])
dur_tst = np.zeros(X_tst.shape[0])
for i_segment in range(n_segments):
tmp = bayes.predict(X_tst[:, :, :int((1 + i_segment) * segment_time * fs)])
idx = np.logical_and(tmp >= 0, dur_tst == 0)
yh_tst[idx] = tmp[idx]
dur_tst[idx] = (1 + i_segment) * segment_time
if np.all(dur_tst > 0):
break
# Compute accuracy
accuracy_bds0[i_fold] = np.mean(yh_tst == y_tst)
duration_bds0[i_fold] = np.mean(dur_tst)
# Compute ITR
itr_bds0 = pyntbci.utilities.itr(n_classes, accuracy_bds0, duration_bds0 + inter_trial_time)
# Plot accuracy (over folds)
fig, ax = plt.subplots(3, 1, figsize=(15, 8), sharex=True)
ax[0].bar(np.arange(n_folds), accuracy_bds0)
ax[0].hlines(np.mean(accuracy_bds0), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[1].bar(np.arange(n_folds), duration_bds0)
ax[1].hlines(np.mean(duration_bds0), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].bar(np.arange(n_folds), itr_bds0)
ax[2].hlines(np.mean(itr_bds0), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].set_xlabel("(test) fold")
ax[0].set_ylabel("accuracy")
ax[1].set_ylabel("duration [s]")
ax[2].set_ylabel("itr [bits/min]")
ax[0].set_title(f"BDS0 dynamic stopping: avg acc {accuracy_bds0.mean():.2f} | " +
f"avg dur {duration_bds0.mean():.2f} | avg itr {itr_bds0.mean():.1f}")
# Print accuracy (average and standard deviation over folds)
print("BDS0:")
print(f"\tAccuracy: avg={accuracy_bds0.mean():.2f} with std={accuracy_bds0.std():.2f}")
print(f"\tDuration: avg={duration_bds0.mean():.2f} with std={duration_bds0.std():.2f}")
print(f"\tITR: avg={itr_bds0.mean():.1f} with std={itr_bds0.std():.2f}")
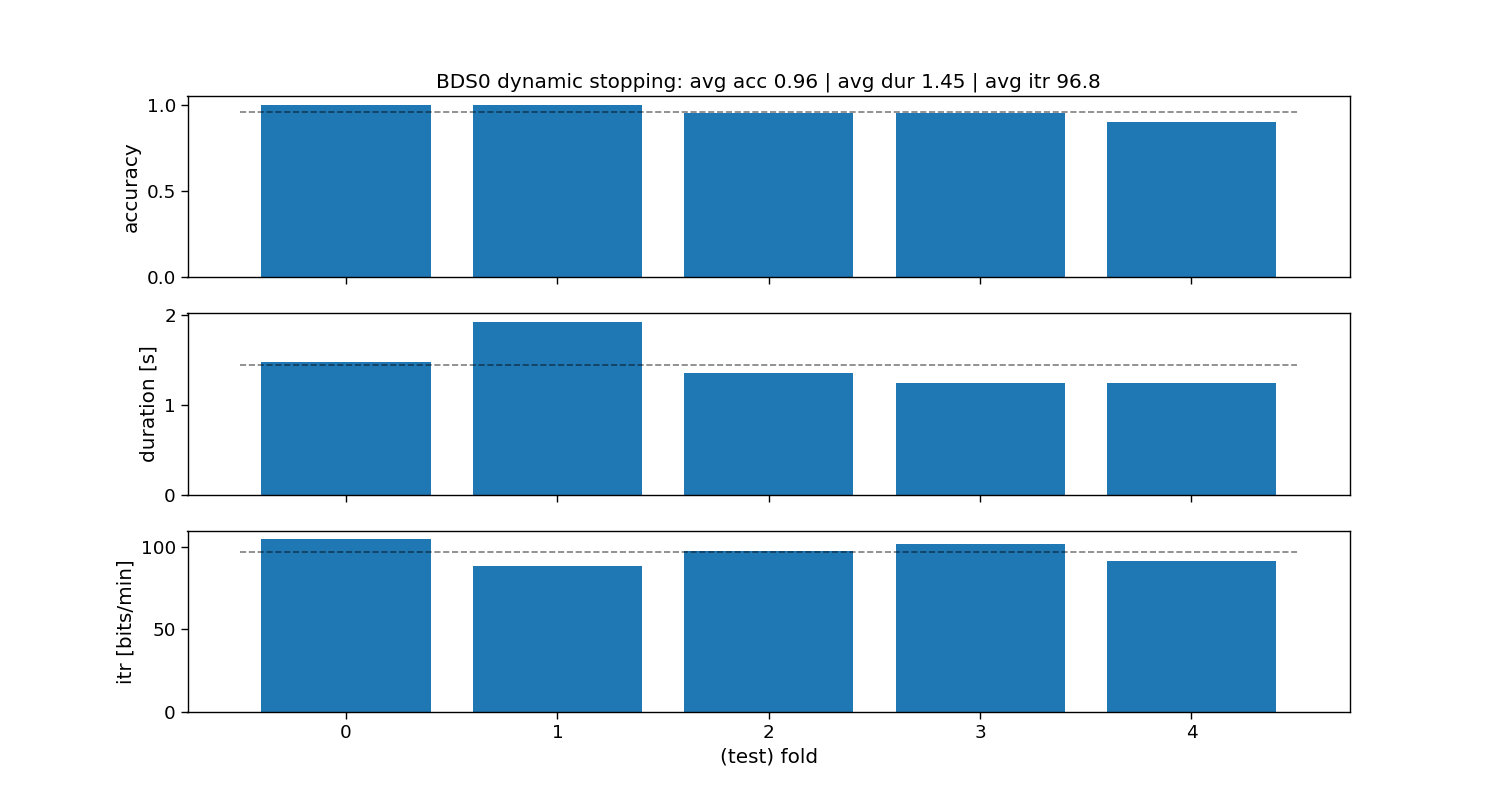
BDS0:
Accuracy: avg=0.96 with std=0.04
Duration: avg=1.45 with std=0.25
ITR: avg=96.8 with std=6.01
Bayesian dynamic stopping (BDS1)
The Bayesian method fits Gaussian distributions for target and non-target responses, and calculates a stopping threshold using these and a cost criterion. This method comes in three flavours: bds0, bds1, and bds2.
References:
response brain-computer interfacing
# Cost ratio and target probabilities
cr = 1.0
target_pf = 0.05
target_pd = 0.80
# Loop folds
accuracy_bds1 = np.zeros(n_folds)
duration_bds1 = np.zeros(n_folds)
for i_fold in range(n_folds):
# Split data to train and valid set
X_trn, y_trn = X[folds != i_fold, :, :n_samples], y[folds != i_fold]
X_tst, y_tst = X[folds == i_fold, :, :n_samples], y[folds == i_fold]
# Train template-matching classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="inner")
bayes = pyntbci.stopping.BayesStopping(rcca, segment_time, fs, method="bds1", cr=cr, target_pf=target_pf,
target_pd=target_pd, max_time=trial_time)
bayes.fit(X_trn, y_trn)
# Apply template-matching classifier
yh_tst = np.zeros(X_tst.shape[0])
dur_tst = np.zeros(X_tst.shape[0])
for i_segment in range(n_segments):
tmp = bayes.predict(X_tst[:, :, :int((1 + i_segment) * segment_time * fs)])
idx = np.logical_and(tmp >= 0, dur_tst == 0)
yh_tst[idx] = tmp[idx]
dur_tst[idx] = (1 + i_segment) * segment_time
if np.all(dur_tst > 0):
break
# Compute accuracy
accuracy_bds1[i_fold] = np.mean(yh_tst == y_tst)
duration_bds1[i_fold] = np.mean(dur_tst)
# Compute ITR
itr_bds1 = pyntbci.utilities.itr(n_classes, accuracy_bds1, duration_bds1 + inter_trial_time)
# Plot accuracy (over folds)
fig, ax = plt.subplots(3, 1, figsize=(15, 8), sharex=True)
ax[0].bar(np.arange(n_folds), accuracy_bds1)
ax[0].hlines(np.mean(accuracy_bds1), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[1].bar(np.arange(n_folds), duration_bds1)
ax[1].hlines(np.mean(duration_bds1), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].bar(np.arange(n_folds), itr_bds1)
ax[2].hlines(np.mean(itr_bds1), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].set_xlabel("(test) fold")
ax[0].set_ylabel("accuracy")
ax[1].set_ylabel("duration [s]")
ax[2].set_ylabel("itr [bits/min]")
ax[0].set_title(f"BDS1 dynamic stopping: avg acc {accuracy_bds1.mean():.2f} | " +
f"avg dur {duration_bds1.mean():.2f} | avg itr {itr_bds1.mean():.1f}")
# Print accuracy (average and standard deviation over folds)
print("BDS1:")
print(f"\tAccuracy: avg={accuracy_bds1.mean():.2f} with std={accuracy_bds1.std():.2f}")
print(f"\tDuration: avg={duration_bds1.mean():.2f} with std={duration_bds1.std():.2f}")
print(f"\tITR: avg={itr_bds1.mean():.1f} with std={itr_bds1.std():.2f}")
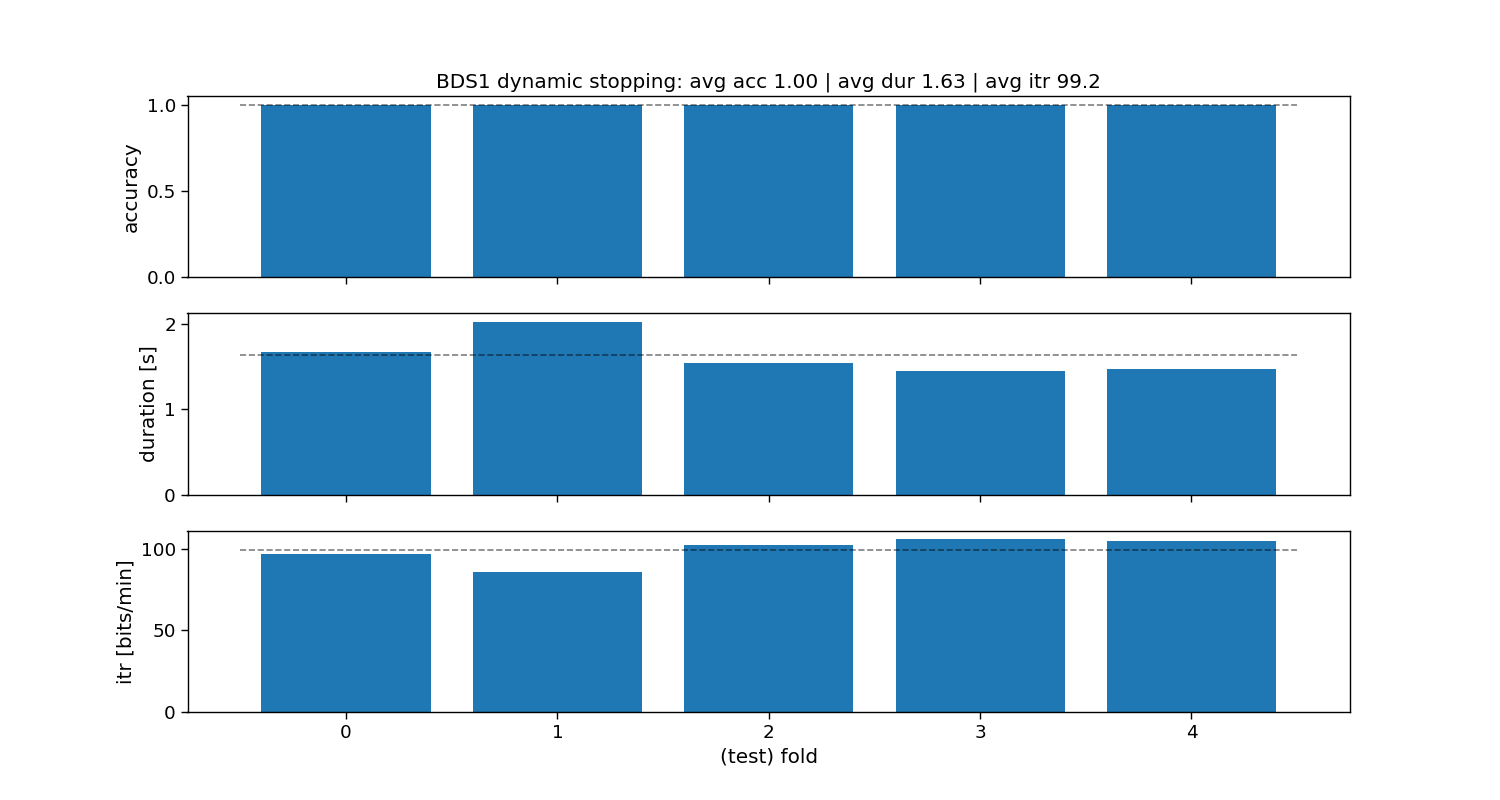
BDS1:
Accuracy: avg=1.00 with std=0.00
Duration: avg=1.63 with std=0.21
ITR: avg=99.2 with std=7.31
Bayesian dynamic stopping (BDS2)
The Bayesian method fits Gaussian distributions for target and non-target responses, and calculates a stopping threshold using these and a cost criterion. This method comes in three flavours: bds0, bds1, and bds2.
References:
response brain-computer interfacing
# Cost ratio and target probabilities
cr = 1.0
target_pf = 0.05
target_pd = 0.80
# Loop folds
accuracy_bds2 = np.zeros(n_folds)
duration_bds2 = np.zeros(n_folds)
for i_fold in range(n_folds):
# Split data to train and valid set
X_trn, y_trn = X[folds != i_fold, :, :n_samples], y[folds != i_fold]
X_tst, y_tst = X[folds == i_fold, :, :n_samples], y[folds == i_fold]
# Train template-matching classifier
rcca = pyntbci.classifiers.rCCA(stimulus=V, fs=fs, event=event, encoding_length=encoding_length,
onset_event=onset_event, score_metric="inner")
bayes = pyntbci.stopping.BayesStopping(rcca, segment_time, fs, method="bds2", cr=cr, target_pf=target_pf,
target_pd=target_pd, max_time=trial_time)
bayes.fit(X_trn, y_trn)
# Apply template-matching classifier
yh_tst = np.zeros(X_tst.shape[0])
dur_tst = np.zeros(X_tst.shape[0])
for i_segment in range(n_segments):
tmp = bayes.predict(X_tst[:, :, :int((1 + i_segment) * segment_time * fs)])
idx = np.logical_and(tmp >= 0, dur_tst == 0)
yh_tst[idx] = tmp[idx]
dur_tst[idx] = (1 + i_segment) * segment_time
if np.all(dur_tst > 0):
break
# Compute accuracy
accuracy_bds2[i_fold] = np.mean(yh_tst == y_tst)
duration_bds2[i_fold] = np.mean(dur_tst)
# Compute ITR
itr_bds2 = pyntbci.utilities.itr(n_classes, accuracy_bds2, duration_bds2 + inter_trial_time)
# Plot accuracy (over folds)
fig, ax = plt.subplots(3, 1, figsize=(15, 8), sharex=True)
ax[0].bar(np.arange(n_folds), accuracy_bds2)
ax[0].hlines(np.mean(accuracy_bds2), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[1].bar(np.arange(n_folds), duration_bds2)
ax[1].hlines(np.mean(duration_bds2), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].bar(np.arange(n_folds), itr_bds2)
ax[2].hlines(np.mean(itr_bds2), -.5, n_folds - 0.5, linestyle='--', color="k", alpha=0.5)
ax[2].set_xlabel("(test) fold")
ax[0].set_ylabel("accuracy")
ax[1].set_ylabel("duration [s]")
ax[2].set_ylabel("itr [bits/min]")
ax[0].set_title(f"BDS2 dynamic stopping: avg acc {accuracy_bds2.mean():.2f} | " +
f"avg dur {duration_bds2.mean():.2f} | avg itr {itr_bds2.mean():.1f}")
# Print accuracy (average and standard deviation over folds)
print("BDS2:")
print(f"\tAccuracy: avg={accuracy_bds2.mean():.2f} with std={accuracy_bds2.std():.2f}")
print(f"\tDuration: avg={duration_bds2.mean():.2f} with std={duration_bds2.std():.2f}")
print(f"\tITR: avg={itr_bds2.mean():.1f} with std={itr_bds2.std():.2f}")
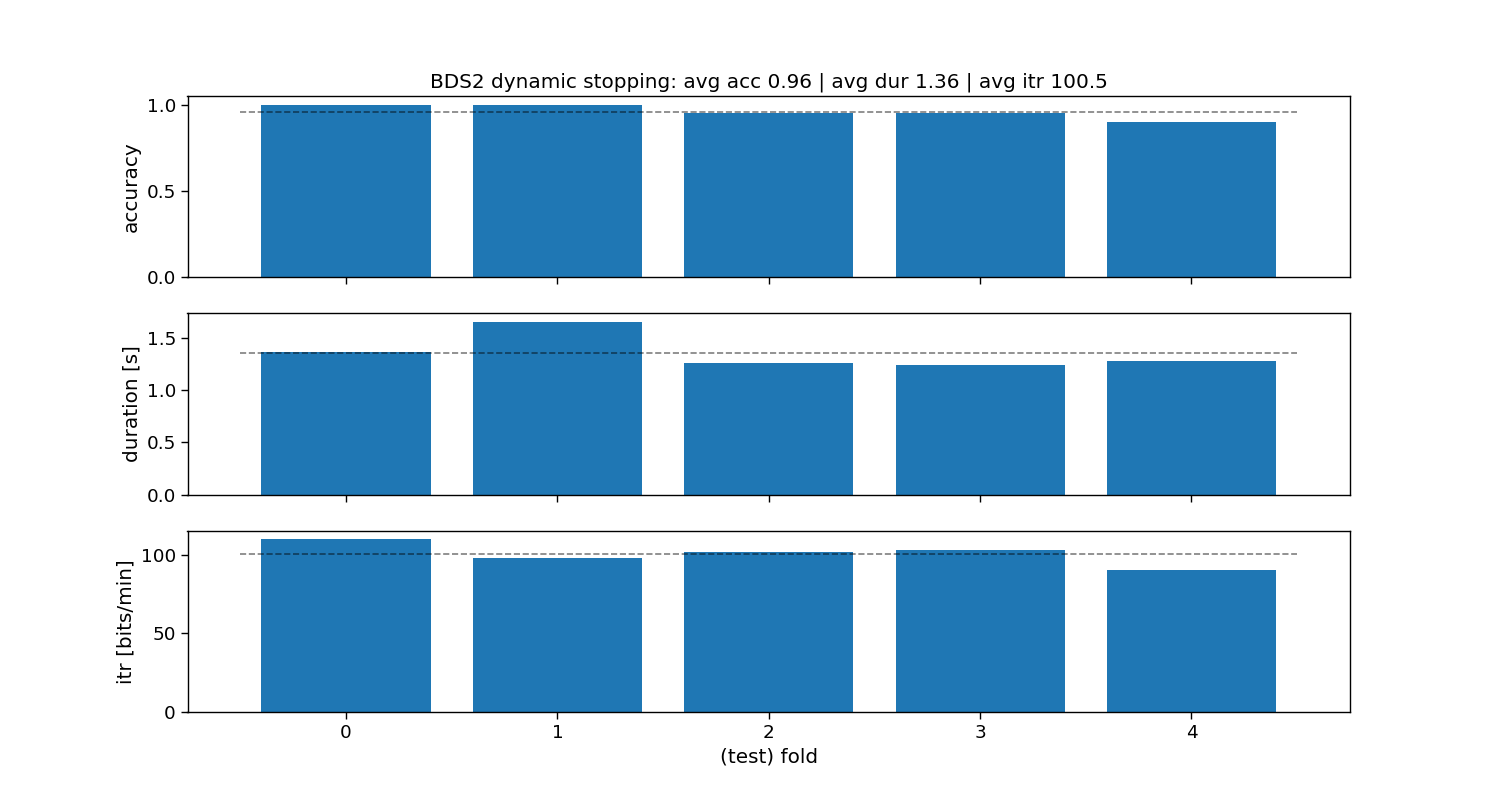
BDS2:
Accuracy: avg=0.96 with std=0.04
Duration: avg=1.36 with std=0.15
ITR: avg=100.5 with std=6.30
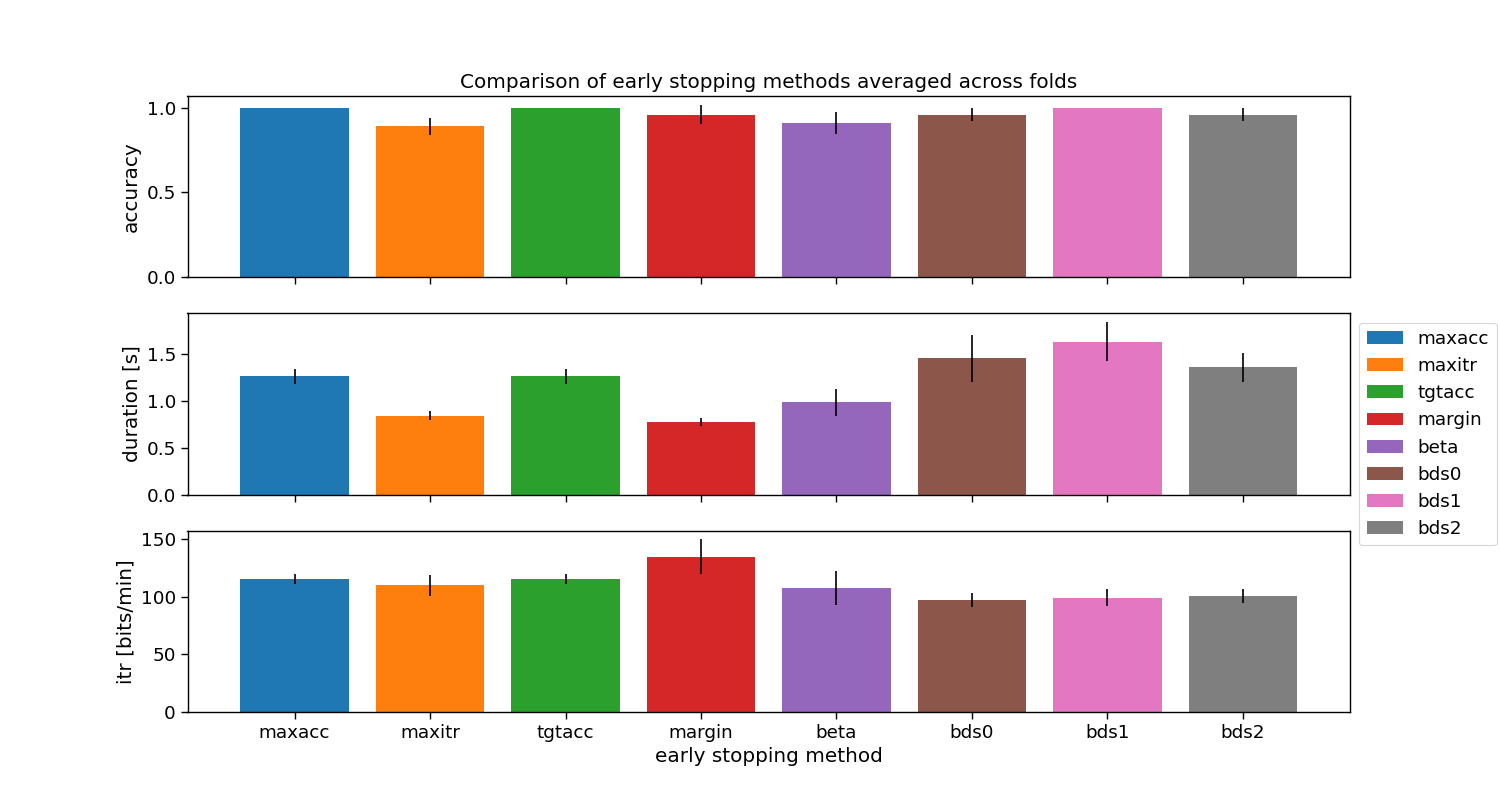
Overall comparison
Comparison of the presented stopping methods. Note, each of these use default parameters that might need fine-tuning. Additionally, the evaluation is performed on a single participant only.
# Plot accuracy
width = 0.8
fig, ax = plt.subplots(3, 1, figsize=(15, 8), sharex=True)
ax[0].bar(0, accuracy_max_acc.mean(), width=width, yerr=accuracy_max_acc.std(), label="maxacc")
ax[0].bar(1, accuracy_max_itr.mean(), width=width, yerr=accuracy_max_itr.std(), label="maxitr")
ax[0].bar(2, accuracy_tgt_acc.mean(), width=width, yerr=accuracy_tgt_acc.std(), label="tgtacc")
ax[0].bar(3, accuracy_margin.mean(), width=width, yerr=accuracy_margin.std(), label="margin")
ax[0].bar(4, accuracy_beta.mean(), width=width, yerr=accuracy_beta.std(), label="beta")
ax[0].bar(5, accuracy_bds0.mean(), width=width, yerr=accuracy_bds0.std(), label="bds0")
ax[0].bar(6, accuracy_bds1.mean(), width=width, yerr=accuracy_bds1.std(), label="bds1")
ax[0].bar(7, accuracy_bds2.mean(), width=width, yerr=accuracy_bds2.std(), label="bds2")
ax[1].bar(0, duration_max_acc.mean(), width=width, yerr=duration_max_acc.std(), label="maxacc")
ax[1].bar(1, duration_max_itr.mean(), width=width, yerr=duration_max_itr.std(), label="maxitr")
ax[1].bar(2, duration_tgt_acc.mean(), width=width, yerr=duration_tgt_acc.std(), label="tgtacc")
ax[1].bar(3, duration_margin.mean(), width=width, yerr=duration_margin.std(), label="margin")
ax[1].bar(4, duration_beta.mean(), width=width, yerr=duration_beta.std(), label="beta")
ax[1].bar(5, duration_bds0.mean(), width=width, yerr=duration_bds0.std(), label="bds0")
ax[1].bar(6, duration_bds1.mean(), width=width, yerr=duration_bds1.std(), label="bds1")
ax[1].bar(7, duration_bds2.mean(), width=width, yerr=duration_bds2.std(), label="bds2")
ax[2].bar(0, itr_max_acc.mean(), width=width, yerr=itr_max_acc.std(), label="maxacc")
ax[2].bar(1, itr_max_itr.mean(), width=width, yerr=itr_max_itr.std(), label="maxitr")
ax[2].bar(2, itr_tgt_acc.mean(), width=width, yerr=itr_tgt_acc.std(), label="tgtacc")
ax[2].bar(3, itr_margin.mean(), width=width, yerr=itr_margin.std(), label="margin")
ax[2].bar(4, itr_beta.mean(), width=width, yerr=itr_beta.std(), label="beta")
ax[2].bar(5, itr_bds0.mean(), width=width, yerr=itr_bds0.std(), label="bds0")
ax[2].bar(6, itr_bds1.mean(), width=width, yerr=itr_bds1.std(), label="bds1")
ax[2].bar(7, itr_bds2.mean(), width=width, yerr=itr_bds2.std(), label="bds2")
ax[2].set_xticks(np.arange(8), ["maxacc", "maxitr", "tgtacc", "margin", "beta", "bds0", "bds1", "bds2"])
ax[2].set_xlabel("early stopping method")
ax[0].set_ylabel("accuracy")
ax[1].set_ylabel("duration [s]")
ax[2].set_ylabel("itr [bits/min]")
ax[1].legend(bbox_to_anchor=(1.0, 1.0))
ax[0].set_title("Comparison of early stopping methods averaged across folds")
# plt.show()
Text(0.5, 1.0, 'Comparison of early stopping methods averaged across folds')
Total running time of the script: (0 minutes 45.202 seconds)